Hi all, this is my first post here.
After months of studying and googling, I've managed to realize a desktop video player:
- wpf/d3dimage for the frontend
- directx 11 for the rendering backend
The two worlds are in communication through surface sharing: that is, directx 11 renders on a shared texture so that d3dimage (d3d9) on wpf side can present the frame.
Directx 11 is fed by GStreamer decoder, producing out I420 planar buffers.
During my research, I've understood that the preferable approach would be to split the buffer into 3 textures (separating the Y-U-V components) and then let a pixel shader reconstruct the ARGB view, so I did it that way.
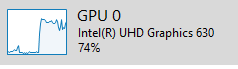
My previous implementation was entirely based on GStreamer plugin, including video output using D3DVideoSink plugin. Comparing the two solutions, the bitter surprise: I've got a +30% of CPU usage and a +45% of GPU usage.
CPU overhead is mainly due to continuous textures/shader_resource_view creation, while GPU overhead…I really don't know.
I've tried to create Dynamic textures once and then map/memcpy/unmap them, but results is worse.
As far as I understood, my DirectX 11 stage is really simple…vertex shader + linear pixel shader, 3 textures (y-u-v), 3 shader resource view, context draw/flush on each frame.
Is there a more efficient way to manage yuv frame?
Am I badly missing something?